Wild Spam Mail
This is the wildest spam mail I have received so far.
The only editing I have done is to anonymize the email addresses and to insert linebreaks in the very long lines.
Date: Sat, 8 Feb 2020 14:51:57 +0000 (UTC)
From: leslie simpson <sandy_johnson2016@XXXXX.com>
Reply-To: lesliesimpson24@XXXXX.com
Subject: HELLO
Good Day,
Please i am contacting you because of the problem we have now at the high sea, now the situation here is getting worse and we've done all we could to put the brain box of the ship in order but to no avail, and beside we just received information from the Signal house that there are sea pirates from Indonesia blocking the sea. They are about 312 KM away from us and the nearest place for this Ship to anchor is Labuan Island somewhere in East Malaysia. As it is now, we are no longer safe because we fear the pirate's attack because the ship is very slow now. We have called for a rescue team but we are yet to get a response from our headquarters.
The captains of the Ship have announced that all passengers should offload their goods for another means of transportation as the SHIP will duck here for other weeks until its safe to continue sailing.
My problem now is my documents and my earn time savings and little part of the money I also took as loan are with me here in the ship, it is which I kept in my cabin safe box. I do not want it stolen from me in the event of any attack. My plan was to use this money USD$23.4 Million United State Dollars to buy Metal oil in drums in Australia and supply to a company in Mexico. I already had a contract agreement with and the documents are for my contract so I have to be careful.
I have discussed with one of the security company here. They will proceed delivery immediately I get a confirmation from you to assist me in receiving this money because there is no bank here and I don't want to lose the money to sea pirates because I know how I suffered for it.
As the Director of Operation in this Ship, it’s not possible for me to move along with the passenger because I have to take care of this ship until all GOODS/PRODUCT are completely discharged.
Now there are so many security companies stands at the seashore and I am thinking of what to do? And at this time I need you to stand by me. I don't know what to do now, I want to quickly send you the documents and money so that you can help me to secure it in your place or into your Bank account until I come. I know we have not met each other but I TRUST you and give you my whole heart so that life can move straight with us and I know you will never disappoint or hurt me. I have learned to take life as it happens as I remember everything happens for a reason, I just can't wait to get off of this issue soon.
quickly forward to me your information as follows to enable me send the documents and money to you immediately through Diplomatic Secured Security Organization:-
Your Full Name:
Your Receiving Address:
Your Country:
your direct Mobile number:
please be fast about it, my dear friend this is very urgent.
I am sitting by the seashore now and waiting for your quick reply. Please I need your prayers this time because we are in a state of confusion praying that nothing happens to us.
Yours faithfully,
Mr. Leslie Simpson
Introduction
I recently got a Roomba (model 966). It's a "small" robot vacuum cleaner that drives around your house and does the day-to-day vacuuming.

In order to be able to limit its working area, you can set up some "light towers" that send out a thin infrared beam, which the Roomba will not cross.
Yes, I am aware that I can connect my model via WiFi and set up no-go zones via a mobile app. But I don't really feel like granting a moving robot with a camera access to Internet. Not that much on the IoT bandwagon.
{kind=link}
Light Tower
The included light tower looks nice, but it is sort of in the way, will probably get kicked around, and runs on batteries.

Full view of the area:

I'd like for the beam to originate from the crack between the door and the trim. As the picture hints, there is around 5mm to use. It would make the setup invisible in practice.
I could take the tower apart and in the process convert it to 5-12V use via some small DC-DC buck converter, but I decided to try to build my own tower. Also to keep the original tower for later.
While I was researching and thinking about this, MKme posted his take on the subject. He uses an MCU to generate the beam encoding. I'd like to try to get a 556 timer to do it. If possible.
Working out the beam encoding
My research showed that there were much disagreement on how the beam should be encoded. This is probably because people were using different versions of the towers and robots.
So: I am using the tower that come with a Roomba 966.
I decided to take a look at the encoding that my tower uses. But I did not have any IR receivers. I did however find a QRD1114 IR reflection detector in an old failed project. I hacked up a quick crappy amplifier using the QRD1114, a BC547, a 10k resistor and a 1k resistor. This is of course an inverting amplifier, thus the scope grabs below are inverted.
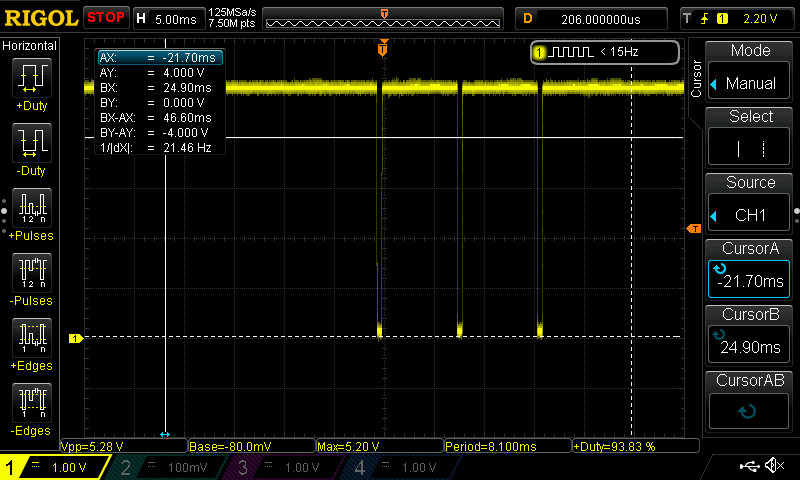
Overview of the signal:
Zoomed in:
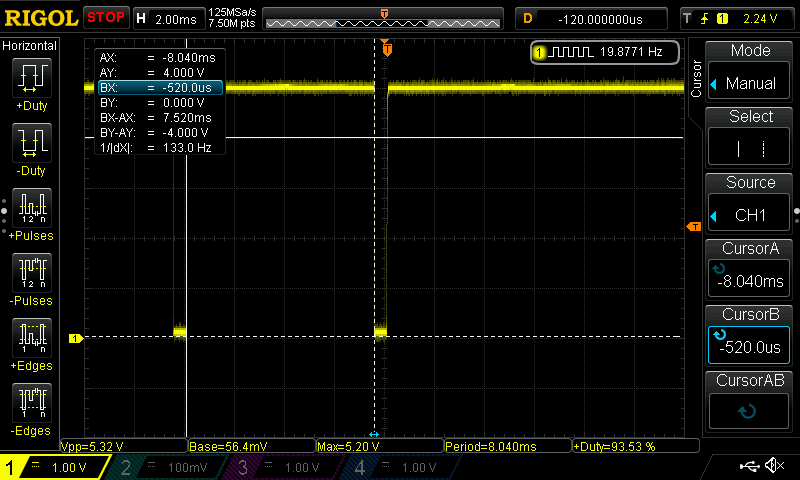
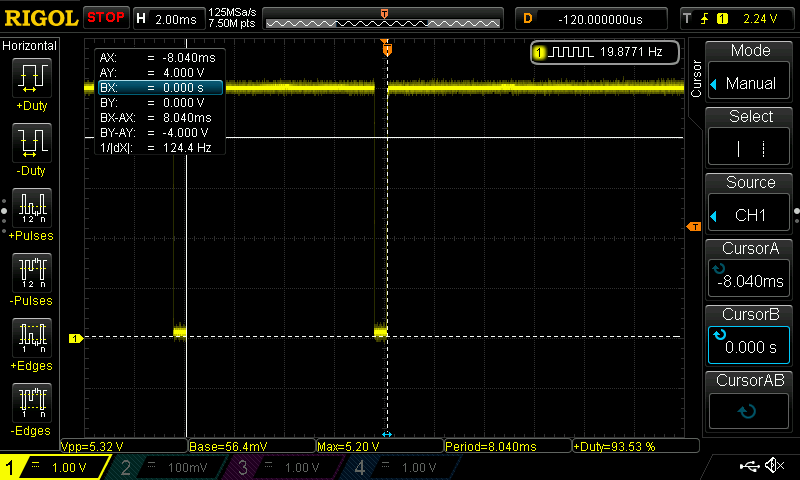 So we have three ~500µs (~8.0ms — ~7.5ms) bursts with two ~7.5ms pauses
in between.
So we have three ~500µs (~8.0ms — ~7.5ms) bursts with two ~7.5ms pauses
in between.
And a zoom on the short bursts:
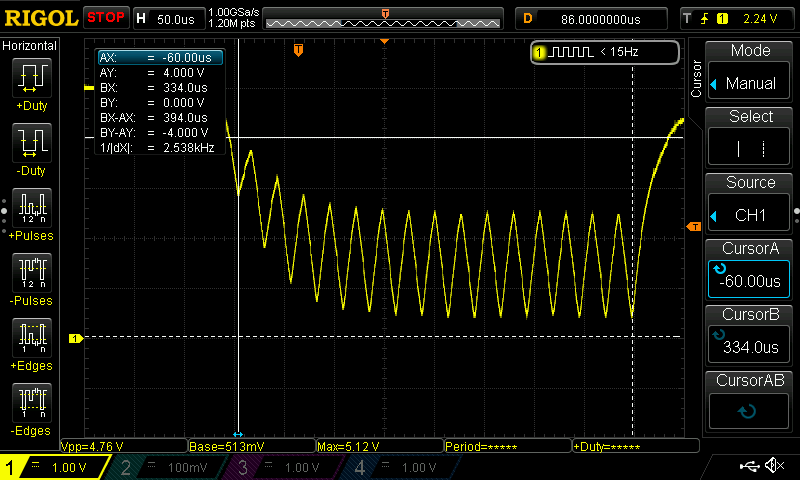 Note that my crappy amplifier has limited bandwidth and thus distorts the
signal, and the "triangle
signal" is in reality a square wave signal that has been low-pass filtered.
But never mind. We can still see that 15 periods take ~394µs, thus one
is ~26.27µs. Giving a frequency of ~38kHz for the bursts.
(This could also have been found as 2.54kHz*15.)
Note that my crappy amplifier has limited bandwidth and thus distorts the
signal, and the "triangle
signal" is in reality a square wave signal that has been low-pass filtered.
But never mind. We can still see that 15 periods take ~394µs, thus one
is ~26.27µs. Giving a frequency of ~38kHz for the bursts.
(This could also have been found as 2.54kHz*15.)
Zoomed further out:
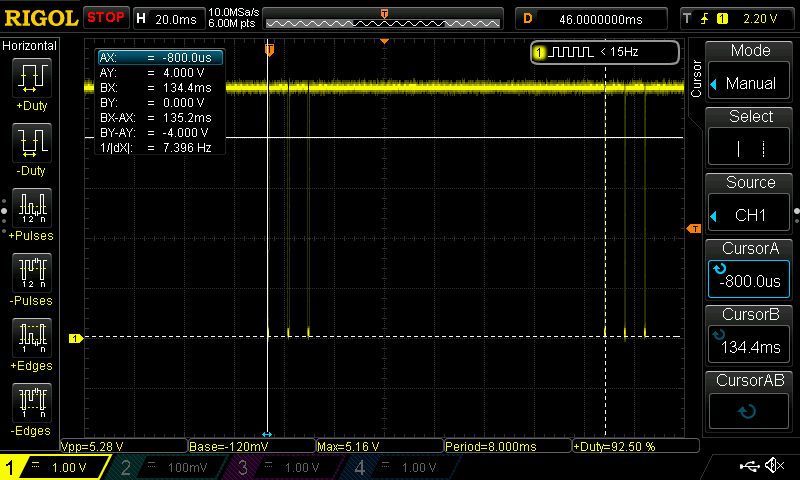 The bursts have ~135ms between starts.
The bursts have ~135ms between starts.
This fits nicely with what (some) others have found: A carrier wave of 38kHz. 500µs on and 7.5ms off repeated 3 times
Assumptions on requirements for the tower
- I assume that iRobot use a decoder chip for the IR signals.
This will probably mean that it will have a fairly narrow bandpass filter around 38kHz for noise reduction.
- I assume that the demodulated IR signal is processed by a microcontroller doing other work too.
This means that the 500µs and 7.5ms timings are way less critical.
- I assume that the 135ms spacing between 3×pulses is only for power saving
This means that this spacing can be ignored. And since I plan to not have my tower run on batteries, this not a real problem.
Testing assumptions
I built a tower prototype using two 555 timers and the QRD1114 on a breadboard:

I tuned the 38kHz carrier frequency pretty closely, but for the 500µs and 7.5ms timings I just used a 555 calculator and tried to get close, using standard component values.
The beam from the IR diode is very weak and very wide, but the Roomba does run away from it.
Thus it looks promising.
The setup draws around 15mA. Which is fine.
Future work
I plan to do the "brains" of each tower using a 556 timer (which is essentially two 555 timers in one chip).
I'm currently waiting for 556 timers and IR diodes to arrive via the 'slow boat from China' before I can continue to do the setup on stripboard.
Also experiments in shaping of the beam will be easier once I have some cheap IR diodes to experiment with.
This will be detailed in part 2. Hopefully as a success story 
Thanks
Big thanks to Paul for talking a lot about 555 timers, and thus pushing me to finally start looking into them.
Thanks to MKme for documenting his version and getting me past the "when I get some time" stage.
Hello
It's been a long time. Mainly because I have not had much to tell here. G+ and twitter seemed to provide an easiser outlet. But G+ is gone (sigh!) and Twitter is only good for some things.
This post is primarily a test to see if my notes are good enough to allow me to start dumping stuff here, again. As an example, I'm currently evaluating if I want to start documeting my electronics projects here.
If you are an intermediate or advanced user of ZFS, then this post is probably not for you.
Introduction
I only recently started looking seriously at ZFS. So far general skepticism about "new stuff" taking care of my precious files, has kept ZFS from being used by me.
But no more. I am going to convert my home server to ZFS, when I get home from The Camp. This post will document some of the decisions and solutions I arrived at while at The Camp.
My requirements for storage are:
- Full disk encryption
- Resilience for single drive failures
- Rock solid filesystem
So far these have been met by gmirror + GBDE + ufs2. But the possibility of having my filesystems share a pool of free space, have had me thinking about ZFS for some time. It would be nice not to have to move stuff around when one filesystem runs out of space.
I was a little worried about how disk failures would manifest themselves, and how they should be handled in order not to loose data. Thus I brought 3 USB disks to The Camp - one with known bad blocks.
Sven Esbjerg held a great ZFS workshop at The Camp, which I attended. It provided a nice crash course in ZFS. During the workshop, I played with setting up two disks as a mirror. When the one with bad blocks gave errors when adding data to the mirror, I could play with replacing it with the spare disk. All worked as expected.
While my requirements included full disk encryption, I also wanted raidz in order to gain more usable disk space.
Looking around I found this convoluted way of doing it, but I wanted to keep it (more) simple - even at the cost of not giving ZFS direct control of the disks. This blog post gave me a nice starting point.
In the end I opted for encrypting the devices with geli, and adding ZFS on top of that.
Configuring ZFS and testing failure
This is done on a laptop, using USB drives, called /dev/daN. Devices on a server would be something like /dev/adaN or /dev/adN.
I will create 3 encrypted devices, tell ZFS to use them, and create a pool spanning them all.
# Create encrypted devices
geli init -s 4096 /dev/da0 # Using a blocksize of 4096 to be prepared
geli init -s 4096 /dev/da1 # for future disks that use 4K blocks
geli init -s 4096 /dev/da2 # da2 is the bad disk
# Attach the devices for use
geli attach /dev/da0
geli attach /dev/da1
geli attach /dev/da2
# Create the zpool (called "tank"), spanning all 3 devices
zpool create tank raidz1 /dev/da0.eli /dev/da1.eli /dev/da2.eli
I then started to fill-up the pool in order to trigger errors from the bad disk.
for i in `jot 10` ; do dd if=/dev/zero bs=1m count=10240 of=/tank/zero1.$i; done
for i in `jot 10` ; do dd if=/dev/zero bs=1m count=10240 of=/tank/zero2.$i; done
# ... etc ...
When the bad blocks were used, errors started to be logged in /var/log/messages, but nothing was registering in ZFS.
From /var/log/messages:
# ...
Jul 25 22:03:39 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): WRITE(10). CDB: 2a 0 c d0 64 20 0 0 80 0
Jul 25 22:03:39 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): CAM status: CCB request completed with an error
Jul 25 22:03:39 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): Retrying command
Jul 25 22:04:53 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): WRITE(10). CDB: 2a 0 c d0 64 20 0 0 80 0
Jul 25 22:04:53 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): CAM status: CCB request completed with an error
Jul 25 22:04:53 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): Retrying command
Jul 25 22:06:06 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): WRITE(10). CDB: 2a 0 c d0 64 20 0 0 80 0
Jul 25 22:06:06 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): CAM status: CCB request completed with an error
Jul 25 22:06:06 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): Retrying command
Jul 25 22:07:20 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): WRITE(10). CDB: 2a 0 c d0 64 20 0 0 80 0
Jul 25 22:07:20 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): CAM status: CCB request completed with an error
Jul 25 22:07:20 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): Retrying command
Jul 25 22:08:34 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): WRITE(10). CDB: 2a 0 c d0 64 20 0 0 80 0
Jul 25 22:08:34 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): CAM status: CCB request completed with an error
Jul 25 22:08:34 <kern.crit> guide kernel: (da2:umass-sim2:2:0:0): Error 5, Retries exhausted
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110071791616, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110071922688, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072053760, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072184832, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072315904, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072446976, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072578048, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110072709120, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110071529472, length=131072)]
Jul 25 22:08:34 <kern.crit> guide kernel: GEOM_ELI: Crypto WRITE request failed (error=5). da2.eli[WRITE(offset=110071660544, length=131072)]
# ...
This kept going for a couple of hours (I kept adding data), while ZFS claimed that all was fine. Finally ZFS saw enough errors, and dropped the bad disk (i forgot to save the output of 'zpool status' here).
I detached the disk from the USB port, and ZFS shows:
guide ~ 90# zpool status
pool: tank
state: DEGRADED
status: One or more devices has been removed by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scan: scrub in progress since Wed Jul 25 22:45:40 2012
188G scanned out of 312G at 38.7M/s, 0h54m to go
0 repaired, 60.17% done
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
da0.eli ONLINE 0 0 0
da1.eli ONLINE 0 0 0
17292134696089706765 REMOVED 0 0 0 was /dev/da2.eli
I have lost a disk, but raidz allows for that, while still allowing access to all data.
Getting access to the pool after reboot
After reboot, the state is:
guide ~ 1# zpool status
pool: tank
state: UNAVAIL
status: One or more devices could not be opened. There are insufficient
replicas for the pool to continue functioning.
action: Attach the missing device and online it using 'zpool online'.
see: http://illumos.org/msg/ZFS-8000-3C
scan: none requested
config:
NAME STATE READ WRITE CKSUM
tank UNAVAIL 0 0 0
raidz1-0 UNAVAIL 0 0 0
7434867841503891175 UNAVAIL 0 0 0 was /dev/da0.eli
2223752624539388409 UNAVAIL 0 0 0 was /dev/da1.eli
17292134696089706765 UNAVAIL 0 0 0 was /dev/da2.eli
Without having attached the geli devices, ZFS cannot find its data, and the pool is offline.
Attach the devices for use:
guide ~ 3# geli attach /dev/da0
Enter passphrase:
guide ~ 4# geli attach /dev/da1
Enter passphrase:
ZFS now finds the devices, but does not mount the data sets.
guide ~ 5# zpool status
pool: tank
state: DEGRADED
status: One or more devices has been removed by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scan: scrub repaired 0 in 1h58m with 0 errors on Thu Jul 26 00:43:43 2012
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
da0.eli ONLINE 0 0 0
da1.eli ONLINE 0 0 0
17292134696089706765 REMOVED 0 0 0 was /dev/da2.eli
Mount the datasets.
guide ~ 8# zfs mount -a
My data are ready to be used again.
If this was not just a test setup, I would get a new drive and add it to the pool.
geli init -s 4096 /dev/da2 # Assuming that da2 was the new drive
geli attach /dev/da2
zpool replace tank 17292134696089706765 /dev/da2.eli
ZFS would now resilver the pool, and after a while the new drive would have all the needed data copied to it, and the pool would again have enough redundancy to allow for the loss of one drive.
Keeping an eye on ZFS
In order to get reminders about the state of ZFS in the nightly emails, I have added ZFS status to /etc/periodic.conf. Furthermore, I have asked the system to run scrub on the pool every 8 days.
guide ~ 22# cat /etc/periodic.conf
daily_status_zfs_enable="YES"
daily_status_zfs_zpool_list_enable="YES"
daily_scrub_zfs_enable="YES"
daily_scrub_zfs_default_threshold=8
Had this been my server, I would now have a good feeling about being informed about the state of my filesystems.
Further thoughts
It is my experience from these tests, that ZFS does not like it when drives belonging to a pool disappear, not even when all filesystems in that pool has been unmounted. Thus I would not recommend using USB drives as removable storage with ZFS for production use.
When replacing a failed drive in a raidz (or a mirror), the new drive should be the same size or larger than the smallest drive at creation of the pool. This should surprise no one.
In practice large drives will differ slightly in size (unless they have the same partnumber). It is therefore prudent to not use the full drive, but leave, say, 100MB-1GB unused at the end. That way it is certain that the new 2TB drive - that you managed to get after hours - will not be 20 sectors too small.
With this in mind, my creation above would have been something like:
guide ~ 2> fgrep sectors: /var/log/messages
Jul 26 18:13:45 <kern.crit> guide kernel: da1: 953869MB (1953525167 512 byte sectors: 255H 63S/T 121601C)
# ... # This time my phone was da0
guide ~ 1# gpart destroy -F da1
guide ~ 2# gpart create -s GPT da1
guide ~ 3# gpart add -b 2048 -s 1953000000 -t freebsd-zfs da1 # (1953525167-1953000000)/2/1024 = 256MB free
# Start at block 2048 means ready for 4K drives
guide ~ 5# gpart show da1
=> 34 1953525100 da1 GPT (931G)
34 2014 - free - (1M)
2048 1953000000 1 freebsd-zfs (931G)
1953002048 523086 - free - (255M)
# Repeat for da2 and da3
guide ~ 10# geli init -s 4096 /dev/da1p1 # Note the use of "p1"
# Repeat for da2 and da3
guide ~ 15# geli attach /dev/da1p1
# Repeat for da2 and da3
guide ~ 20# zpool create tank raidz1 /dev/da1p1.eli /dev/da2p1.eli /dev/da3p1.eli
And we are now ready with .5G space less in tank (256M less at 3 drives, of which 1/3 would have been used for redundancy).
Conclusion
I feel that this way of adding crypto to ZFS is the best way, at least until the day Oracle decides to opensource the changes from v28 to v33. It does encrypt the data plus the redundancy, but I see no real alternative to this, if I want the extra benefits of ZFS.
Jeg fandt dette opslag på min gadedør, da jeg kom hjem fra arbejde idag.

(Klik for større version)
Jeg skal ikke gøre mig klog på baggrunden for situationen.
Bare konstatere at nogen gange går det galt for vores vigtige data.
Og så er godt at have en backup.
Vi, der arbejder professionelt med IT, er sjældent i tvivl om at det er
en god ide at have en grundig backup strategi. En del af os har endda
implementeret noget backup for vores private data.
For vores venner og bekendte, der bruger computere som et nødvendigt redskab, så er det ikke altid indlysende at man bør sikre sig. Og derved kommer de indimellem i klemme, som M. i ovenstående opslag.
Backup strategi
En god strategi ved projektarbejde er at have en USB stick med 7 underkataloger - et for hver ugedag. Hver aften, når man er færdig med dagens arbejde, kopieres alle de projekt relevante filer til dagens katalog.
USB sticken skal derefter placeres et sted der er uafhængigt af computeren, og hvor evt. tyve ikke vil finde den. Hvis både laptop og USB stick mistes samtidig, så er backupen jo intet værd.
Menneskelige fejl i editering og deciderede fejl i den anvendte software kan ødelægge teksten man skriver på. Dette kan oftest reddes ved at gå tilbage til en af de 7 kopier man har tilbage i tiden.
Om man også vil beskytte sig mod brand, eller om man synes at, hvis ens hjem
er brændt af, så er projektet det mindste problem, må man tage stilling til.
Hvis man vil beskytte sig mod brand, så bør man have yderligere to USB sticks.
Den ene har man hjemme og hver gang det er belejligt, så kopierer man alle
projekt relaterede filer til den, og bytter den med den man har liggende
uden for hjemmet (på arbejde, på skolen, hos en ven, ...). På denne måde
roteres de to USB sticks så ofte man kan.
En anden god strategi er at sende alle filerne til sin egen gmail konto
hver aften.
Så ligger data på googles servere, og er altid til at få fat på.
Vejled venner og bekendte om backup
Ovenstående er næppe særligt nyt eller overraskende for læserne af denne blog.
Men for mange af jeres venner er det måske - så det er op til jer at sikre,
at de ikke ender som M. her.
Brug evt. dette opslag som en øjenåbner for de, der ikke umiddelbart kan se pointen i at tage backup.
This blog has been quiet for a long time.
This is mostly due to me being busy, and not having much to write about.
Also, some of the reason is that Anton, who
hosted my blog from the start
in late 2008, announced that he was going to
abandon the old Movable Type blog platform in favor of
ikiwiki.
Not feeling much inclined to use time on a doomed platform, I did not
write.
Back in January, Anton helped me migrate my stuff to ikiwiki, and all that that was left was some css hacking. However Open Source Days 2011 was right around the corner, and the new blog project was put on hold.
But now it is finished, and my new ikiwiki powered blog is live.
During the process, I discovered that ikiwiki is very easy to host, thus I
moved the blog to my own server. Thanks much to Anton for the hosting of the
old blog, and all the resulting Movable Type hacking and patching.
I can only recommend that you look into ikiwiki, just as Anton writes
here.
I have tried to keep old links working, but stuff is bound to be forgotten ...
Comment here to have it fixed.
Today I got this mail from Amazon.
Greetings from Amazon.co.uk,
As someone who has purchased or rated "Toy Story 2 (2 Disc Collector's Edition) [1999] [DVD]" or other titles in the Regular Stores > Audio Description category, you might like to know that "It's Complicated [Blu-ray] [2009]" is now available. You can order yours for just £15.71 (37% off the RRP) by following the link below.
It's Complicated [Blu-ray] [2009]
Meryl Streep
I mean, really, how is a Meryl Streep movie in any way comparable to Toy Story 2?
And what is it with this Regular Stores > Audio Description category?
Please try harder.
Det er altid en underlig tom fornemmelse at vågne søndag morgen efter Open Source Days.
Flere måneders målrettet indsats er kulmineret. Og festen er nu vel overstået.
Pludselig er der ikke en mulliard opgaver der skal huskes, og en zillion ting der skal koordineres med 'de andre'[1].
Morgenen (dvs. formiddagen/middagen) er foregået halvt i zombie tilstand.
Det lokale brunch sted havde lukket, så jeg har holdt den gående på bagerbrød og Red Bull.
Jeg er helt klart blevet for gammel til at tage 4 pre-konference dage og 2 16 timers konferencedage (incl. en pæn del efter-konference-øl) uden men.
Jeg stod som de foregående år for at sikre at der var net og strøm til udstillere og brugergrupper.
Til at hjælpe med dette havde jeg igen iår et super Net-crew, bestående af:
Lars Thegler, Jenny Hadfield, Henrik Andersen, Jesper Frilund, Michel "Yuki" Inoue,
Jon Erichsen, Asbjørn Thegler & Søren Schrøder [2]
Tak gutter, det var igen iår en fornøjelse at arbejde sammen med jer.
(Det skal kraftigt understreges at vi ikke havde noget med det trådløse net at gøre. Det er 100% konfigureret og administreret af IT-U.)
Også tak til alle vores konference hjælpere. Det er jeres fortjeneste at alt det praktiske under konferencen har forløbet så glat som det gjorde. I er alt for mange til at nævne her, men i ved hvem i er.
Det er min opfattelse, at alt på konferencen forløb uden reelle problemer.
Jeg havde derfor tid til at se flere af foredragene. Og de jeg var nødt til at misse håber jeg at DKUUGs video team fik båndet. Hold øje med websiden for at se når de er online.
Tilbage er nu at få klaret de løse administrative ender, hvor den vigtigste er at sikre at vi får aflagt regnskab til vores ejere, DKUUG. Uden DKUUGs velvillige økomnomiske backing havde der ikke været nogen Open Source Days konference.
På det mere personlige plan er det pludselig gået op for mig, at vasketøjskurven har fået rekord top på, og at de steder min Roomba ikke kan nå, har et decideret gråt og let uldent skær i forårssolen. Papirene i TODO bunken på skrivebordet ser ud til at være i akut fare for at komme i skred og planterne ser temmeligt indtørrede ud. Afgjort en god plan også at tage en fridag mandag.
![]()
[1] Hanne, Kristian, Peter og Sidsel
[2] Sorteret efter 2. bogstav i fornavn. Hvorfor ikke?
Billedet herunder viser IT-universitetet i forårssolen.
Det er her Open Source Days 2010 løber af stabelen fredag og lørdag.
Open Source Days[1] er for mig en af de vigtige events, der bebuder forårets komme. Og arbejdet med at få konferencen op at stå, har altid hjulpet med at få de kedelige og triste vintermåneder til at gå hurtigere.
Nu er der kun de sidste hektiske 1½ dage tilbage til festen begynder.
Kommer du?

![]()
[1] inklusive de tidligere konferencer under LinuxForum navnet.
Anders and I were doing our usual after-lunch-walk, when we passed this sight.

It is not as bad as some of the pictures found on the net, but still funny.
This blog is powered by ikiwiki.